

API and Documentation
Edward’s design reflects the building blocks for probabilistic modeling. It defines interchangeable components, enabling rapid experimentation and research with probabilistic models.
Edward is named after the innovative statistician George Edward Pelham Box. Edward follows Box’s philosophy of statistics and machine learning (Box, 1976).
First gather data from some real-world phenomena. Then cycle through Box’s loop (Blei, 2014).
- Build a probabilistic model of the phenomena.
- Reason about the phenomena given model and data.
- Criticize the model, revise and repeat.
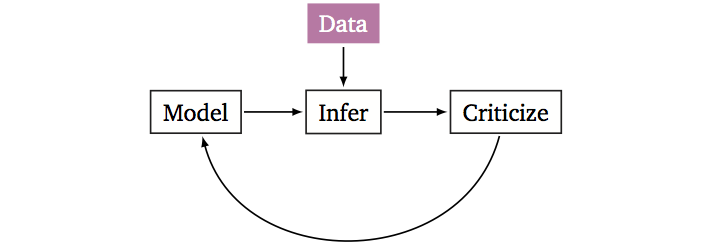
Here’s a toy example. A child flips a coin ten times, with the set of outcomes being [0, 1, 0, 0, 0, 0, 0, 0, 0, 1], where 0 denotes tails and 1 denotes heads. She is interested in the probability that the coin lands heads. To analyze this, she first builds a model: suppose she assumes the coin flips are independent and land heads with the same probability. Second, she reasons about the phenomenon: she infers the model’s hidden structure given data. Finally, she criticizes the model: she analyzes whether her model captures the real-world phenomenon of coin flips. If it doesn’t, then she may revise the model and repeat.
Navigate modules enabling this analysis above. See the reference page for a list of the API.
References
Blei, D. M. (2014). Build, compute, critique, repeat: Data analysis with latent variable models. Annual Review of Statistics and Its Application, 1, 203–232.
Box, G. E. (1976). Science and statistics. Journal of the American Statistical Association, 71(356), 791–799.