

Unsupervised Learning
In unsupervised learning, the task is to infer hidden structure from unlabeled data, comprised of training examples \(\{x_n\}\).
We demonstrate with an example in Edward. An interactive version with Jupyter notebook is available here.
Data
Use a simulated data set of 2-dimensional data points \(\mathbf{x}_n\in\mathbb{R}^2\).
def build_toy_dataset(N):
pi = np.array([0.4, 0.6])
mus = [[1, 1], [-1, -1]]
stds = [[0.1, 0.1], [0.1, 0.1]]
x = np.zeros((N, 2), dtype=np.float32)
for n in range(N):
k = np.argmax(np.random.multinomial(1, pi))
x[n, :] = np.random.multivariate_normal(mus[k], np.diag(stds[k]))
return x
N = 500 # number of data points
D = 2 # dimensionality of data
x_train = build_toy_dataset(N)We visualize the generated data points.
plt.scatter(x_train[:, 0], x_train[:, 1])
plt.axis([-3, 3, -3, 3])
plt.show()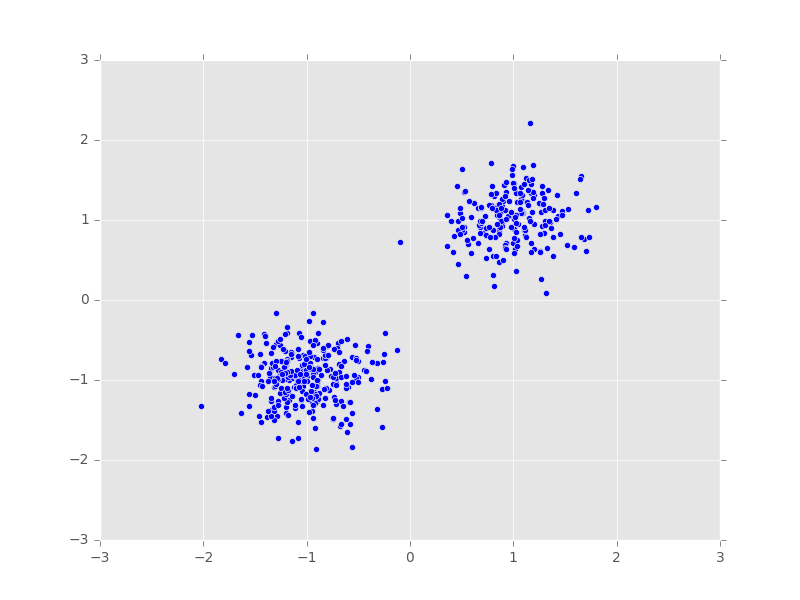
Model
A mixture model is a model typically used for clustering. It assigns a mixture component to each data point, and this mixture component determines the distribution that the data point is generated from. A mixture of Gaussians uses Gaussian distributions to generate this data (Bishop, 2006).
For a set of \(N\) data points, the likelihood of each observation \(\mathbf{x}_n\) is
\[\begin{aligned} p(\mathbf{x}_n \mid \pi, \mu, \sigma) &= \sum_{k=1}^K \pi_k \, \text{Normal}(\mathbf{x}_n \mid \mu_k, \sigma_k).\end{aligned}\]
The latent variable \(\pi\) is a \(K\)-dimensional probability vector which mixes individual Gaussian distributions, each characterized by a mean \(\mu_k\) and standard deviation \(\sigma_k\).
Define the prior on \(\pi\in[0,1]\) such that \(\sum_{k=1}^K\pi_k=1\) to be
\[\begin{aligned} p(\pi) &= \text{Dirichlet}(\pi \mid \alpha \mathbf{1}_{K})\end{aligned}\]
for fixed \(\alpha=1\). Define the prior on each component \(\mathbf{\mu}_k\in\mathbb{R}^D\) to be
\[\begin{aligned} p(\mathbf{\mu}_k) &= \text{Normal}(\mathbf{\mu}_k \mid \mathbf{0}, \mathbf{I}).\end{aligned}\]
Define the prior on each component \(\mathbf{\sigma}_k^2\in\mathbb{R}^D\) to be
\[\begin{aligned} p(\mathbf{\sigma}_k^2) &= \text{InverseGamma}(\mathbf{\sigma}_k^2 \mid a, b).\end{aligned}\]
We build two versions of the model in Edward: one jointly with the mixture assignments \(c_n\in\{0,\ldots,K-1\}\) as latent variables, and another with them summed out.
The joint version includes an explicit latent variable for the mixture assignments. We implement this with the ParamMixture random variable; it takes as input the mixing probabilities, the components’ parameters, and the distribution of the components. It is the distribution of the mixture conditional on mixture assignments. (Note we can also write this separately by first building a ‘Categorical‘ random variable for z and then building x; ParamMixture avoids requiring tf.gather which is slightly more efficient.)
from edward.models import Dirichlet, InverseGamma, MultivariateNormalDiag, \
Normal, ParamMixture
K = 2 # number of components
pi = Dirichlet(tf.ones(K))
mu = Normal(tf.zeros(D), tf.ones(D), sample_shape=K)
sigmasq = InverseGamma(tf.ones(D), tf.ones(D), sample_shape=K)
x = ParamMixture(pi, {'loc': mu, 'scale_diag': tf.sqrt(sigmasq)},
MultivariateNormalDiag,
sample_shape=N)
z = x.catThe collapsed version marginalizes out the mixture assignments. We implement this with the Mixture random variable; it takes as input a Categorical distribution and a list of individual distribution components. It is the distribution of the mixture summing out the mixture assignments.
from edward.models import Categorical, Dirichlet, InverseGamma, Mixture, \
MultivariateNormalDiag, Normal
K = 2 # number of components
pi = Dirichlet(tf.ones(K))
mu = Normal(tf.zeros(D), tf.ones(D), sample_shape=K)
sigma = InverseGamma(tf.ones(D), tf.ones(D), sample_shape=K)
cat = Categorical(probs=pi, sample_shape=N)
components = [
MultivariateNormalDiag(mu[k], sigma[k], sample_shape=N)
for k in range(K)]
x = Mixture(cat=cat, components=components)We will use the joint version in this analysis.
Inference
Each distribution in the model is written with conjugate priors, so we can use Gibbs sampling. It performs Markov chain Monte Carlo by iterating over draws from the complete conditionals of each distribution, i.e., each distribution conditional on a previously drawn value. First we set up Empirical random variables which will approximate the posteriors using the collection of samples.
T = 500 # number of MCMC samples
qpi = Empirical(tf.get_variable(
"qpi/params", [T, K],
initializer=tf.constant_initializer(1.0 / K)))
qmu = Empirical(tf.get_variable(
"qmu/params", [T, K, D],
initializer=tf.zeros_initializer()))
qsigmasq = Empirical(tf.get_variable(
"qsigmasq/params", [T, K, D],
initializer=tf.ones_initializer()))
qz = Empirical(tf.get_variable(
"qz/params", [T, N],
initializer=tf.zeros_initializer(),
dtype=tf.int32))Run Gibbs sampling. We write the training loop explicitly, so that we can track the cluster means as the sampler progresses.
inference = ed.Gibbs({pi: qpi, mu: qmu, sigmasq: qsigmasq, z: qz},
data={x: x_train})
inference.initialize()
sess = ed.get_session()
tf.global_variables_initializer().run()
t_ph = tf.placeholder(tf.int32, [])
running_cluster_means = tf.reduce_mean(qmu.params[:t_ph], 0)
for _ in range(inference.n_iter):
info_dict = inference.update()
inference.print_progress(info_dict)
t = info_dict['t']
if t % inference.n_print == 0:
print("\nInferred cluster means:")
print(sess.run(running_cluster_means, {t_ph: t - 1}))See the associated Jupyter notebook for the inferred cluster means tracked during training.
Criticism
We visualize the predicted memberships of each data point. We pick the cluster assignment which produces the highest posterior predictive density for each data point.
To do this, we first draw a sample from the posterior and calculate a a \(N\times K\) matrix of log-likelihoods, one for each data point \(\mathbf{x}_n\) and cluster assignment \(k\). We perform this averaged over 100 posterior samples.
# Calculate likelihood for each data point and cluster assignment,
# averaged over many posterior samples. ``x_post`` has shape (N, 100, K, D).
mu_sample = qmu.sample(100)
sigmasq_sample = qsigmasq.sample(100)
x_post = Normal(loc=tf.ones([N, 1, 1, 1]) * mu_sample,
scale=tf.ones([N, 1, 1, 1]) * tf.sqrt(sigmasq_sample))
x_broadcasted = tf.tile(tf.reshape(x_train, [N, 1, 1, D]), [1, 100, K, 1])
# Sum over latent dimension, then average over posterior samples.
# ``log_liks`` ends up with shape (N, K).
log_liks = x_post.log_prob(x_broadcasted)
log_liks = tf.reduce_sum(log_liks, 3)
log_liks = tf.reduce_mean(log_liks, 1)We then take the \(\arg\max\) along the columns (cluster assignments).
clusters = tf.argmax(log_liks, 1).eval()Plot the data points, colored by their predicted membership.
plt.scatter(x_train[:, 0], x_train[:, 1], c=clusters, cmap=cm.bwr)
plt.axis([-3, 3, -3, 3])
plt.title("Predicted cluster assignments")
plt.show()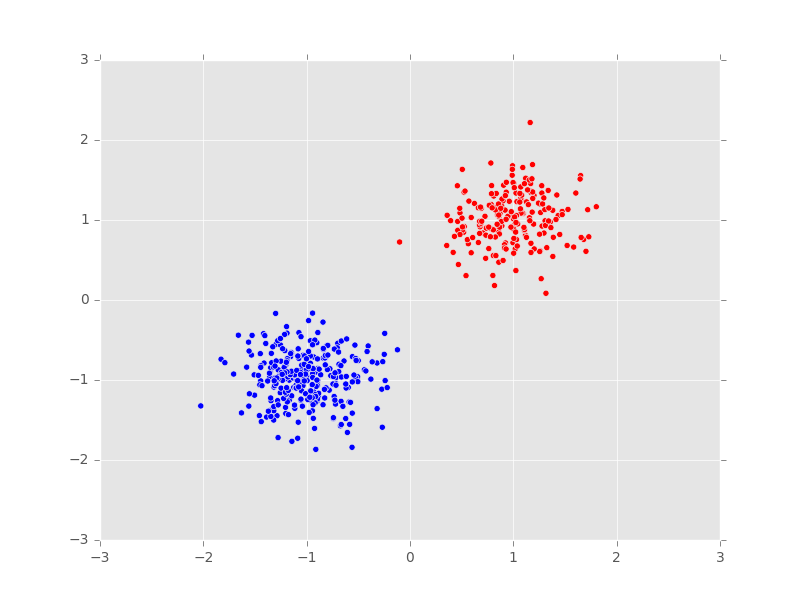
The model has correctly clustered the data.
Remarks: The log-sum-exp trick
For a collapsed mixture model, implementing the log density can be tricky. In general, the log density is \[\begin{aligned}
\log p(\pi) +
\Big[ \sum_{k=1}^K \log p(\mathbf{\mu}_k) + \log
p(\mathbf{\sigma}_k) \Big] +
\sum_{n=1}^N \log p(\mathbf{x}_n \mid \pi, \mu, \sigma),\end{aligned}\] where the likelihood is \[\begin{aligned}
\sum_{n=1}^N \log p(\mathbf{x}_n \mid \pi, \mu, \sigma)
&=
\sum_{n=1}^N \log \sum_{k=1}^K \pi_k \, \text{Normal}(\mathbf{x}_n \mid
\mu_k, \sigma_k).\end{aligned}\] To prevent numerical instability, we’d like to work on the log-scale, \[\begin{aligned}
\sum_{n=1}^N \log p(\mathbf{x}_n \mid \pi, \mu, \sigma)
&=
\sum_{n=1}^N \log \sum_{k=1}^K \exp\Big(
\log \pi_k + \log \text{Normal}(\mathbf{x}_n \mid \mu_k, \sigma_k)\Big).\end{aligned}\] This expression involves a log sum exp operation, which is numerically unstable as exponentiation will often lead to one value dominating the rest. Therefore we use the log-sum-exp trick. It is based on the identity \[\begin{aligned}
\mathbf{x}_{\mathrm{max}}
&=
\arg\max \mathbf{x},
\\
\log \sum_i \exp(\mathbf{x}_i)
&=
\log \Big(\exp(\mathbf{x}_{\mathrm{max}}) \sum_i \exp(\mathbf{x}_i -
\mathbf{x}_{\mathrm{max}})\Big)
\\
&=
\mathbf{x}_{\mathrm{max}} + \log \sum_i \exp(\mathbf{x}_i -
\mathbf{x}_{\mathrm{max}}).\end{aligned}\] Subtracting the maximum value before taking the log-sum-exp leads to more numerically stable output. The Mixture random variable implements this trick for calculating the log-density.
References
Bishop, C. M. (2006). Pattern recognition and machine learning. Springer New York.